Antoine Beaupr : A comparison of cryptographic keycards
An earlier article showed that
private key storage is an important problem to solve in any
cryptographic system and established keycards as a good way to store
private key material offline. But which keycard should we use? This
article examines the form factor, openness, and performance of four
keycards to try to help readers choose the one that will fit their
needs.
I have personally been using a YubiKey NEO, since a 2015
announcement
on GitHub promoting two-factor authentication. I was also able to hook
up my SSH authentication key into the YubiKey's 2048 bit RSA slot. It
seemed natural to move the other subkeys onto the keycard, provided that
performance was sufficient. The mail client that I use,
(Notmuch), blocks when decrypting messages,
which could be a serious problems on large email threads from encrypted
mailing lists.
So I built a test harness and got access to some more keycards: I bought
a FST-01 from its creator,
Yutaka Niibe, at the last DebConf and Nitrokey donated a Nitrokey
Pro. I also
bought a YubiKey 4
when I got the NEO. There are of course other keycards out there, but
those are the ones I could get my hands on. You'll notice none of those
keycards have a physical keypad to enter passwords, so they are all
vulnerable to keyloggers that could extract the key's PIN. Keep in mind,
however, that even with the PIN, an attacker could only ask the keycard
to decrypt or sign material but not extract the key that is protected by
the card's firmware.
Form factor
Form factor
 The four keycards have similar form factors: they all connect to a
standard USB port, although both YubiKey keycards have a capacitive
button by which the user triggers two-factor authentication and the
YubiKey 4 can also require a button
press
to confirm private key use. The YubiKeys feel sturdier than the other
two. The NEO has withstood two years of punishment in my pockets along
with the rest of my "real" keyring and there is only minimal wear on the
keycard in the picture. It's also thinner so it fits well on the
keyring.
The FST-01 stands out from the other two with its minimal design. Out of
the box, the FST-01 comes without a case, so the circuitry is exposed.
This is deliberate: one of its goals is to be as transparent as
possible, both in terms of software and hardware design and you
definitely get that feeling at the physical level. Unfortunately, that
does mean it feels more brittle than other models: I wouldn't carry it
in my pocket all the time, although there is a
case
that may protect the key a little better, but it does not provide an
easy way to hook it into a keyring. In the group picture above, the
FST-01 is the pink plastic thing, which is a rubbery casing I received
along with the device when I got it.
Notice how the USB connectors of the YubiKeys differ from the other two:
while the FST-01 and the Nitrokey have standard USB connectors, the
YubiKey has only a "half-connector", which is what makes it thinner than
the other two. The "Nano" form factor takes this even further and almost
disappears in the USB port. Unfortunately, this arrangement means the
YubiKey NEO often comes loose and falls out of the USB port, especially
when connected to a laptop. On my workstation, however, it usually stays
put even with my whole keyring hanging off of it. I suspect this adds
more strain to the host's USB port but that's a tradeoff I've lived with
without any noticeable wear so far. Finally, the NEO has this peculiar
feature of supporting NFC for certain operations, as LWN previously
covered, but I haven't used that
feature yet.
The Nitrokey Pro looks like a normal USB key, in contrast with the other
two devices. It does feel a little brittle when compared with the
YubiKey, although only time will tell how much of a beating it can take.
It has a small ring in the case so it is possible to carry it directly
on your keyring, but I would be worried the cap would come off
eventually. Nitrokey devices are also two times thicker than the Yubico
models which makes them less convenient to carry around on keyrings.
The four keycards have similar form factors: they all connect to a
standard USB port, although both YubiKey keycards have a capacitive
button by which the user triggers two-factor authentication and the
YubiKey 4 can also require a button
press
to confirm private key use. The YubiKeys feel sturdier than the other
two. The NEO has withstood two years of punishment in my pockets along
with the rest of my "real" keyring and there is only minimal wear on the
keycard in the picture. It's also thinner so it fits well on the
keyring.
The FST-01 stands out from the other two with its minimal design. Out of
the box, the FST-01 comes without a case, so the circuitry is exposed.
This is deliberate: one of its goals is to be as transparent as
possible, both in terms of software and hardware design and you
definitely get that feeling at the physical level. Unfortunately, that
does mean it feels more brittle than other models: I wouldn't carry it
in my pocket all the time, although there is a
case
that may protect the key a little better, but it does not provide an
easy way to hook it into a keyring. In the group picture above, the
FST-01 is the pink plastic thing, which is a rubbery casing I received
along with the device when I got it.
Notice how the USB connectors of the YubiKeys differ from the other two:
while the FST-01 and the Nitrokey have standard USB connectors, the
YubiKey has only a "half-connector", which is what makes it thinner than
the other two. The "Nano" form factor takes this even further and almost
disappears in the USB port. Unfortunately, this arrangement means the
YubiKey NEO often comes loose and falls out of the USB port, especially
when connected to a laptop. On my workstation, however, it usually stays
put even with my whole keyring hanging off of it. I suspect this adds
more strain to the host's USB port but that's a tradeoff I've lived with
without any noticeable wear so far. Finally, the NEO has this peculiar
feature of supporting NFC for certain operations, as LWN previously
covered, but I haven't used that
feature yet.
The Nitrokey Pro looks like a normal USB key, in contrast with the other
two devices. It does feel a little brittle when compared with the
YubiKey, although only time will tell how much of a beating it can take.
It has a small ring in the case so it is possible to carry it directly
on your keyring, but I would be worried the cap would come off
eventually. Nitrokey devices are also two times thicker than the Yubico
models which makes them less convenient to carry around on keyrings.
Open and closed designs
The FST-01 is as open as hardware comes, down to the PCB design
available as KiCad files in this Git
repository. The
software running on the card is the
Gnuk firmware that implements the
OpenPGP card protocol, but you can
also get it with firmware implementing a true random number generator
(TRNG) called
NeuG
(pronounced "noisy"); the device is
programmable through a
standard Serial Wire
Debug (SWD) port. The
Nitrokey Start model also runs the Gnuk firmware. However, the Nitrokey
website announces only ECC and RSA 2048-bit
support for the Start, while the FST-01 also supports RSA-4096.
Nitrokey's founder Jan Suhr, in a private email, explained that this is
because "Gnuk doesn't support RSA-3072 or larger at a reasonable speed".
Its devices (the Pro, Start, and HSM models) use a similar chip to the
FST-01: the STM32F103
microcontroller.
 Nitrokey also publishes its hardware designs, on
GitHub, which shows the Pro is basically a
fork of the FST-01, according to the
ChangeLog.
I opened the case to confirm it was using the STM MCU, something I
should warn you against; I broke one of the pins holding it together
when opening it so now it's even more fragile. But at least, I was able
to confirm it was built using the STM32F103TBU6 MCU, like the FST-01.
Nitrokey also publishes its hardware designs, on
GitHub, which shows the Pro is basically a
fork of the FST-01, according to the
ChangeLog.
I opened the case to confirm it was using the STM MCU, something I
should warn you against; I broke one of the pins holding it together
when opening it so now it's even more fragile. But at least, I was able
to confirm it was built using the STM32F103TBU6 MCU, like the FST-01.
 But this is where the comparison ends: on the back side, we find a SIM
card reader that holds the OpenPGP
card that, in turn, holds
the private key material and does the cryptographic operations. So, in
effect, the Nitrokey Pro is really a evolution of the original OpenPGP
card readers.
Nitrokey confirmed the OpenPGP card featured in the Pro is the same as
the one shipped by
the Free Software Foundation Europe (FSFE): the
BasicCard built by ZeitControl. Those cards,
however, are covered by NDAs and the firmware is only partially open
source.
This makes the Nitrokey Pro less open than the FST-01, but that's an
inevitable tradeoff when choosing a design based on the OpenPGP cards,
which Suhr described to me as "pretty proprietary". There are other
keycards out there, however, for example the
SLJ52GDL150-150k
smartcard suggested by
Debian developer Yves-Alexis Perez, which he prefers as it is certified
by French and German authorities. In that blog post, he also said he was
experimenting with the GPL-licensed OpenPGP
applet implemented by the French
ANSSI.
But the YubiKey devices are even further away in the closed-design
direction. Both the hardware designs and firmware are proprietary. The
YubiKey NEO, for example, cannot be upgraded at all, even though it is
based on an open firmware. According to Yubico's
FAQ,
this is due to "best security practices": "There is a 'no upgrade'
policy for our devices since nothing, including malware, can write to
the firmware."
I find this decision questionable in a context where security updates
are often more important than trying to design a bulletproof design,
which may simply be impossible. And the YubiKey NEO did suffer from
critical security
issue
that allowed attackers to bypass the PIN protection on the card, which
raises the question of the actual protection of the private key material
on those cards. According to Niibe, "some OpenPGP cards store the
private key unencrypted. It is a common attitude for many smartcard
implementations", which was confirmed by Suhr: "the private key is
protected by hardware mechanisms which prevent its extraction and
misuse". He is referring to the use of tamper
resistance.
After that security issue, there was no other option for YubiKey NEO
users than to get a new keycard (for free, thankfully) from Yubico,
which also meant discarding the private key material on the key. For
OpenPGP keys, this may mean having to bootstrap the web of trust from
scratch if the keycard was responsible for the main certification key.
But at least the NEO is running free software based on the OpenPGP card
applet and the
source is still available on
GitHub. The YubiKey 4, on the
other hand, is now closed
source,
which was controversial when the new model was announced last year. It
led the main Linux Foundation system administrator, Konstantin
Ryabitsev, to withdraw his
endorsement
of Yubico products. In response, Yubico argued that this approach was
essential to the security of its
devices,
which are now based on "a secure chip, which has built-in
countermeasures to mitigate a long list of attacks". In particular, it
claims that:
But this is where the comparison ends: on the back side, we find a SIM
card reader that holds the OpenPGP
card that, in turn, holds
the private key material and does the cryptographic operations. So, in
effect, the Nitrokey Pro is really a evolution of the original OpenPGP
card readers.
Nitrokey confirmed the OpenPGP card featured in the Pro is the same as
the one shipped by
the Free Software Foundation Europe (FSFE): the
BasicCard built by ZeitControl. Those cards,
however, are covered by NDAs and the firmware is only partially open
source.
This makes the Nitrokey Pro less open than the FST-01, but that's an
inevitable tradeoff when choosing a design based on the OpenPGP cards,
which Suhr described to me as "pretty proprietary". There are other
keycards out there, however, for example the
SLJ52GDL150-150k
smartcard suggested by
Debian developer Yves-Alexis Perez, which he prefers as it is certified
by French and German authorities. In that blog post, he also said he was
experimenting with the GPL-licensed OpenPGP
applet implemented by the French
ANSSI.
But the YubiKey devices are even further away in the closed-design
direction. Both the hardware designs and firmware are proprietary. The
YubiKey NEO, for example, cannot be upgraded at all, even though it is
based on an open firmware. According to Yubico's
FAQ,
this is due to "best security practices": "There is a 'no upgrade'
policy for our devices since nothing, including malware, can write to
the firmware."
I find this decision questionable in a context where security updates
are often more important than trying to design a bulletproof design,
which may simply be impossible. And the YubiKey NEO did suffer from
critical security
issue
that allowed attackers to bypass the PIN protection on the card, which
raises the question of the actual protection of the private key material
on those cards. According to Niibe, "some OpenPGP cards store the
private key unencrypted. It is a common attitude for many smartcard
implementations", which was confirmed by Suhr: "the private key is
protected by hardware mechanisms which prevent its extraction and
misuse". He is referring to the use of tamper
resistance.
After that security issue, there was no other option for YubiKey NEO
users than to get a new keycard (for free, thankfully) from Yubico,
which also meant discarding the private key material on the key. For
OpenPGP keys, this may mean having to bootstrap the web of trust from
scratch if the keycard was responsible for the main certification key.
But at least the NEO is running free software based on the OpenPGP card
applet and the
source is still available on
GitHub. The YubiKey 4, on the
other hand, is now closed
source,
which was controversial when the new model was announced last year. It
led the main Linux Foundation system administrator, Konstantin
Ryabitsev, to withdraw his
endorsement
of Yubico products. In response, Yubico argued that this approach was
essential to the security of its
devices,
which are now based on "a secure chip, which has built-in
countermeasures to mitigate a long list of attacks". In particular, it
claims that:
A commercial-grade AVR or ARM controller is unfit to be used in a
security product. In most cases, these controllers are easy to attack,
from breaking in via a debug/JTAG/TAP port to probing memory contents.
Various forms of fault injection and side-channel analysis are
possible, sometimes allowing for a complete key recovery in a
shockingly short period of time.
While I understand those concerns, they eventually come down to the
trust you have in an organization. Not only do we have to trust Yubico,
but also hardware manufacturers and designs they have chosen. Every step
in the hidden supply chain is then trusted to make correct technical
decisions and not introduce any backdoors.
History, unfortunately, is not on Yubico's side: Snowden revealed the
example of RSA security
accepting what renowned cryptographer Bruce Schneier described as a
"bribe"
from the NSA to weaken its ECC implementation, by using the presumably
backdoored Dual_EC_DRBG
algorithm. What makes Yubico or its suppliers so different from RSA
Security? Remember that RSA Security used to be an adamant opponent to
the degradation of encryption standards, campaigning against the
Clipper chip in the first
crypto wars.
Even if we trust the Yubico supply chain, how can we trust a closed
design using what basically amounts to security through obscurity?
Publicly auditable designs are an important tradition in cryptography,
and that principle shouldn't stop when software is frozen into silicon.
In fact, a critical vulnerability called
ROCA
disclosed recently affects closed "smartcards" like the
YubiKey 4
and allows full private key recovery from the public key if the key was
generated on a vulnerable keycard. When speaking with Ars
Technica,
the researchers outlined the importance of open designs and questioned
the reliability of certification:
Our work highlights the dangers of keeping the design secret and the
implementation closed-source, even if both are thoroughly analyzed and
certified by experts. The lack of public information causes a delay in
the discovery of flaws (and hinders the process of checking for them),
thereby increasing the number of already deployed and affected devices
at the time of detection.
This issue with open hardware designs seems to be recurring topic of
conversation on the Gnuk mailing
list. For
example, there was a
discussion
in September 2017 regarding possible hardware vulnerabilities in the STM
MCU that would allow extraction of encrypted key material from the key.
Niibe referred to a
talk
presented at the WOOT 17
workshop, where Johannes Obermaier and Stefan Tatschner, from the
Fraunhofer Institute, demonstrated attacks against the STMF0 family
MCUs. It is still unclear if those attacks also apply to the older STMF1
design used in the FST-01, however. Furthermore, extracted private key
material is still protected by user passphrase, but the Gnuk uses a weak
key derivation function, so brute-forcing attacks may be possible.
Fortunately, there is work in progress to
make GnuPG hash the passphrase before sending it to the keycard, which
should make such attacks harder if not completely pointless.
When asked about the Yubico claims in a private email, Niibe did
recognize that "it is true that there are more weak points in general
purpose implementations than special implementations". During the last
DebConf in Montreal, Niibe
explained:
If you don't trust me, you should not buy from me. Source code
availability is only a single factor: someone can maliciously replace
the firmware to enable advanced attacks.
Niibe recommends to "build the firmware yourself", also saying the
design of the FST-01 uses normal hardware that "everyone can replicate".
Those advantages are hard to deny for a cryptographic system: using more
generic components makes it harder for hostile parties to mount targeted
attacks.
A counter-argument here is that it can be difficult for a regular user
to audit such designs, let alone physically build the device from
scratch but, in a mailing list discussion, Debian developer Ian Jackson
explained
that:
You don't need to be able to validate it personally. The thing spooks
most hate is discovery. Backdooring supposedly-free hardware is harder
(more costly) because it comes with greater risk of discovery.
To put it concretely: if they backdoor all of them, someone (not
necessarily you) might notice. (Backdooring only yours involves
messing with the shipping arrangements and so on, and supposes that
you specifically are of interest.)
Since that, as far as we know, the STM microcontrollers are not
backdoored, I would tend to favor those devices instead of proprietary
ones, as such a backdoor would be more easily detectable than in a
closed design. Even though physical attacks may be possible against
those microcontrollers, in the end, if an attacker has physical access
to a keycard, I consider the key compromised, even if it has the best
chip on the market. In our email exchange, Niibe argued that "when a
token is lost, it is better to revoke keys, even if the token is
considered secure enough". So like any other device, physical compromise
of tokens may mean compromise of the key and should trigger
key-revocation procedures.
Algorithms and performance
To establish reliable performance results, I wrote a benchmark program
naively called crypto-bench
that could produce comparable results between the different keys. The
program takes each algorithm/keycard combination and runs 1000
decryptions of a 16-byte file (one AES-128 block) using GnuPG, after
priming it to get the password cached. I assume the overhead of GnuPG
calls to be negligible, as it should be the same across all tokens, so
comparisons are possible. AES encryption is constant across all tests as
it is always performed on the host and fast enough to be irrelevant in
the tests.
I used the following:
- Intel(R) Core(TM) i3-6100U CPU @ 2.30GHz running Debian 9
("stretch"/stable amd64), using GnuPG 2.1.18-6 (from the stable
Debian package)
- Nitrokey Pro 0.8 (latest firmware)
- FST-01, running Gnuk version 1.2.5 (latest firmware)
- YubiKey NEO OpenPGP applet 1.0.10 (not upgradable)
- YubiKey 4 4.2.6 (not upgradable)
I ran crypto-bench for each keycard, which resulted in the following:
Algorithm
Device
Mean time (s)
ECDH-Curve25519
CPU
0.036
FST-01
0.135
RSA-2048
CPU
0.016
YubiKey-4
0.162
Nitrokey-Pro
0.610
YubiKey-NEO
0.736
FST-01
1.265
RSA-4096
CPU
0.043
YubiKey-4
0.875
Nitrokey-Pro
3.150
FST-01
8.218
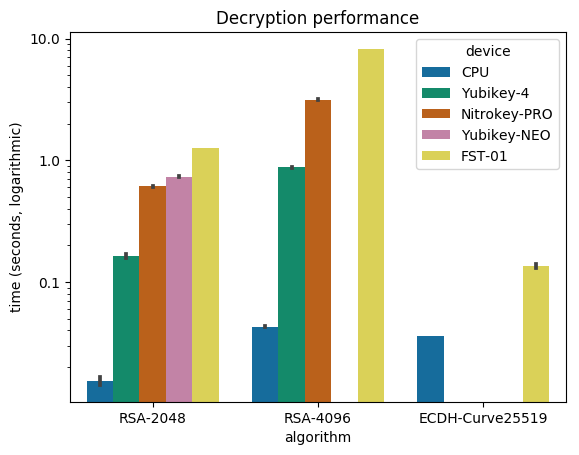 There we see the performance of the four keycards I tested, compared
with the same operations done without a keycard: the "CPU" device. That
provides the baseline time of GnuPG decrypting the file. The first
obvious observation is that using a keycard is slower: in the best
scenario (FST-01 + ECC) we see a four-fold slowdown, but in the worst
case (also FST-01, but RSA-4096), we see a catastrophic 200-fold
slowdown. When I
presented
the results on the Gnuk mailing list, GnuPG developer Werner Koch
confirmed those "numbers are as expected":
There we see the performance of the four keycards I tested, compared
with the same operations done without a keycard: the "CPU" device. That
provides the baseline time of GnuPG decrypting the file. The first
obvious observation is that using a keycard is slower: in the best
scenario (FST-01 + ECC) we see a four-fold slowdown, but in the worst
case (also FST-01, but RSA-4096), we see a catastrophic 200-fold
slowdown. When I
presented
the results on the Gnuk mailing list, GnuPG developer Werner Koch
confirmed those "numbers are as expected":
With a crypto chip RSA is much faster. By design the Gnuk can't be as
fast - it is just a simple MCU. However, using Curve25519 Gnuk is
really fast.
And yes, the FST-01 is really fast at doing ECC, but it's also the only
keycard that handles ECC in my tests; the Nitrokey Start and Nitrokey
HSM should support it as well, but I haven't been able to test those
devices. Also note that the YubiKey NEO doesn't support RSA-4096 at all,
so we can only compare RSA-2048 across keycards. We should note,
however, that ECC is slower than RSA on the CPU, which suggests the
Gnuk ECC implementation used by the FST-01 is exceptionally fast.
In
discussions
about improving the performance of the FST-01, Niibe estimated the user
tolerance threshold to be "2 seconds decryption time". In a new
design
using the STM32L432 microcontroller, Aurelien Jarno was able to bring
the numbers for RSA-2048 decryption from 1.27s down to 0.65s, and for
RSA-4096, from 8.22s down to 3.87s seconds. RSA-4096 is still beyond the
two-second threshold, but at least it brings the FST-01 close to the
YubiKey NEO and Nitrokey Pro performance levels.
We should also underline the superior performance of the YubiKey 4:
whatever that thing is doing, it's doing it faster than anyone else. It
does RSA-4096 faster than the FST-01 does RSA-2048, and almost as fast
as the Nitrokey Pro does RSA-2048. We should also note that the Nitrokey
Pro also fails to cross the two-second threshold for RSA-4096
decryption.
For me, the FST-01's stellar performance with ECC outshines the other
devices. Maybe it says more about the efficiency of the algorithm than
the FST-01 or Gnuk's design, but it's definitely an interesting avenue
for people who want to deploy those modern algorithms. So, in terms of
performance, it is clear that both the YubiKey 4 and the FST-01 take the
prize in their own areas (RSA and ECC, respectively).
Conclusion
In the above presentation, I have evaluated four cryptographic keycards
for use with various OpenPGP operations. What the results show is that
the only efficient way of storing a 4096-bit encryption key on a keycard
would be to use the YubiKey 4. Unfortunately, I do not feel we should
put our trust in such closed designs so I would argue you should either
stick with 2048-bit encryption subkeys or keep the keys on disk.
Considering that losing such a key would be catastrophic, this might be
a good approach anyway. You should also consider switching to ECC
encryption: even though it may not be supported everywhere, GnuPG
supports having multiple encryption subkeys on a keyring: if one
algorithm is unsupported (e.g. GnuPG 1.4 doesn't support ECC), it will
fall back to a supported algorithm (e.g. RSA). Do not forget your
previously encrypted material doesn't magically re-encrypt itself using
your new encryption subkey, however.
For authentication and signing keys, speed is not such an issue, so I
would warmly recommend either the Nitrokey Pro or Start, or the FST-01,
depending on whether you want to start experimenting with ECC
algorithms. Availability also seems to be an issue for the FST-01. While
you can generally get the device when you meet Niibe in person for a few
bucks (I bought mine for around \$30 Canadian), the Seeed online
shop says the device is out of
stock
at the time of this writing, even though Jonathan McDowell
said
that may be inaccurate in a debian-project discussion. Nevertheless,
this issue may make the Nitrokey devices more attractive. When deciding
on using the Pro or Start, Suhr offered the following advice:
In practice smart card security has been proven to work well (at least
if you use a decent smart card). Therefore the Nitrokey Pro should be
used for high security cases. If you don't trust the smart card or if
Nitrokey Start is just sufficient for you, you can choose that one.
This is why we offer both models.
So far, I have created a signing subkey and moved that and my
authentication key to the YubiKey NEO, because it's a device I
physically trust to keep itself together in my pockets and I was already
using it. It has served me well so far, especially with its extra
features like U2F and
HOTP
support, which I use frequently. Those features are also available on
the Nitrokey Pro, so that may be an alternative if I lose the YubiKey. I
will probably move my main certification key to the FST-01 and a
LUKS-encrypted USB disk, to keep that certification key offline but
backed up on two different devices. As for the encryption key, I'll wait
for keycard performance to improve, or simply switch my whole keyring to
ECC and use the FST-01 or Nitrokey Start for that purpose.
[The author would like to thank Nitrokey for providing hardware for
testing.]
This article first appeared in the Linux Weekly News.

 Nitrokey also publishes its hardware designs, on
GitHub, which shows the Pro is basically a
fork of the FST-01, according to the
ChangeLog.
I opened the case to confirm it was using the STM MCU, something I
should warn you against; I broke one of the pins holding it together
when opening it so now it's even more fragile. But at least, I was able
to confirm it was built using the STM32F103TBU6 MCU, like the FST-01.
Nitrokey also publishes its hardware designs, on
GitHub, which shows the Pro is basically a
fork of the FST-01, according to the
ChangeLog.
I opened the case to confirm it was using the STM MCU, something I
should warn you against; I broke one of the pins holding it together
when opening it so now it's even more fragile. But at least, I was able
to confirm it was built using the STM32F103TBU6 MCU, like the FST-01.
 But this is where the comparison ends: on the back side, we find a SIM
card reader that holds the OpenPGP
card that, in turn, holds
the private key material and does the cryptographic operations. So, in
effect, the Nitrokey Pro is really a evolution of the original OpenPGP
card readers.
Nitrokey confirmed the OpenPGP card featured in the Pro is the same as
the one shipped by
the Free Software Foundation Europe (FSFE): the
BasicCard built by ZeitControl. Those cards,
however, are covered by NDAs and the firmware is only partially open
source.
This makes the Nitrokey Pro less open than the FST-01, but that's an
inevitable tradeoff when choosing a design based on the OpenPGP cards,
which Suhr described to me as "pretty proprietary". There are other
keycards out there, however, for example the
SLJ52GDL150-150k
smartcard suggested by
Debian developer Yves-Alexis Perez, which he prefers as it is certified
by French and German authorities. In that blog post, he also said he was
experimenting with the GPL-licensed OpenPGP
applet implemented by the French
ANSSI.
But the YubiKey devices are even further away in the closed-design
direction. Both the hardware designs and firmware are proprietary. The
YubiKey NEO, for example, cannot be upgraded at all, even though it is
based on an open firmware. According to Yubico's
FAQ,
this is due to "best security practices": "There is a 'no upgrade'
policy for our devices since nothing, including malware, can write to
the firmware."
I find this decision questionable in a context where security updates
are often more important than trying to design a bulletproof design,
which may simply be impossible. And the YubiKey NEO did suffer from
critical security
issue
that allowed attackers to bypass the PIN protection on the card, which
raises the question of the actual protection of the private key material
on those cards. According to Niibe, "some OpenPGP cards store the
private key unencrypted. It is a common attitude for many smartcard
implementations", which was confirmed by Suhr: "the private key is
protected by hardware mechanisms which prevent its extraction and
misuse". He is referring to the use of tamper
resistance.
After that security issue, there was no other option for YubiKey NEO
users than to get a new keycard (for free, thankfully) from Yubico,
which also meant discarding the private key material on the key. For
OpenPGP keys, this may mean having to bootstrap the web of trust from
scratch if the keycard was responsible for the main certification key.
But at least the NEO is running free software based on the OpenPGP card
applet and the
source is still available on
GitHub. The YubiKey 4, on the
other hand, is now closed
source,
which was controversial when the new model was announced last year. It
led the main Linux Foundation system administrator, Konstantin
Ryabitsev, to withdraw his
endorsement
of Yubico products. In response, Yubico argued that this approach was
essential to the security of its
devices,
which are now based on "a secure chip, which has built-in
countermeasures to mitigate a long list of attacks". In particular, it
claims that:
But this is where the comparison ends: on the back side, we find a SIM
card reader that holds the OpenPGP
card that, in turn, holds
the private key material and does the cryptographic operations. So, in
effect, the Nitrokey Pro is really a evolution of the original OpenPGP
card readers.
Nitrokey confirmed the OpenPGP card featured in the Pro is the same as
the one shipped by
the Free Software Foundation Europe (FSFE): the
BasicCard built by ZeitControl. Those cards,
however, are covered by NDAs and the firmware is only partially open
source.
This makes the Nitrokey Pro less open than the FST-01, but that's an
inevitable tradeoff when choosing a design based on the OpenPGP cards,
which Suhr described to me as "pretty proprietary". There are other
keycards out there, however, for example the
SLJ52GDL150-150k
smartcard suggested by
Debian developer Yves-Alexis Perez, which he prefers as it is certified
by French and German authorities. In that blog post, he also said he was
experimenting with the GPL-licensed OpenPGP
applet implemented by the French
ANSSI.
But the YubiKey devices are even further away in the closed-design
direction. Both the hardware designs and firmware are proprietary. The
YubiKey NEO, for example, cannot be upgraded at all, even though it is
based on an open firmware. According to Yubico's
FAQ,
this is due to "best security practices": "There is a 'no upgrade'
policy for our devices since nothing, including malware, can write to
the firmware."
I find this decision questionable in a context where security updates
are often more important than trying to design a bulletproof design,
which may simply be impossible. And the YubiKey NEO did suffer from
critical security
issue
that allowed attackers to bypass the PIN protection on the card, which
raises the question of the actual protection of the private key material
on those cards. According to Niibe, "some OpenPGP cards store the
private key unencrypted. It is a common attitude for many smartcard
implementations", which was confirmed by Suhr: "the private key is
protected by hardware mechanisms which prevent its extraction and
misuse". He is referring to the use of tamper
resistance.
After that security issue, there was no other option for YubiKey NEO
users than to get a new keycard (for free, thankfully) from Yubico,
which also meant discarding the private key material on the key. For
OpenPGP keys, this may mean having to bootstrap the web of trust from
scratch if the keycard was responsible for the main certification key.
But at least the NEO is running free software based on the OpenPGP card
applet and the
source is still available on
GitHub. The YubiKey 4, on the
other hand, is now closed
source,
which was controversial when the new model was announced last year. It
led the main Linux Foundation system administrator, Konstantin
Ryabitsev, to withdraw his
endorsement
of Yubico products. In response, Yubico argued that this approach was
essential to the security of its
devices,
which are now based on "a secure chip, which has built-in
countermeasures to mitigate a long list of attacks". In particular, it
claims that:
A commercial-grade AVR or ARM controller is unfit to be used in a security product. In most cases, these controllers are easy to attack, from breaking in via a debug/JTAG/TAP port to probing memory contents. Various forms of fault injection and side-channel analysis are possible, sometimes allowing for a complete key recovery in a shockingly short period of time.While I understand those concerns, they eventually come down to the trust you have in an organization. Not only do we have to trust Yubico, but also hardware manufacturers and designs they have chosen. Every step in the hidden supply chain is then trusted to make correct technical decisions and not introduce any backdoors. History, unfortunately, is not on Yubico's side: Snowden revealed the example of RSA security accepting what renowned cryptographer Bruce Schneier described as a "bribe" from the NSA to weaken its ECC implementation, by using the presumably backdoored Dual_EC_DRBG algorithm. What makes Yubico or its suppliers so different from RSA Security? Remember that RSA Security used to be an adamant opponent to the degradation of encryption standards, campaigning against the Clipper chip in the first crypto wars. Even if we trust the Yubico supply chain, how can we trust a closed design using what basically amounts to security through obscurity? Publicly auditable designs are an important tradition in cryptography, and that principle shouldn't stop when software is frozen into silicon. In fact, a critical vulnerability called ROCA disclosed recently affects closed "smartcards" like the YubiKey 4 and allows full private key recovery from the public key if the key was generated on a vulnerable keycard. When speaking with Ars Technica, the researchers outlined the importance of open designs and questioned the reliability of certification:
Our work highlights the dangers of keeping the design secret and the implementation closed-source, even if both are thoroughly analyzed and certified by experts. The lack of public information causes a delay in the discovery of flaws (and hinders the process of checking for them), thereby increasing the number of already deployed and affected devices at the time of detection.This issue with open hardware designs seems to be recurring topic of conversation on the Gnuk mailing list. For example, there was a discussion in September 2017 regarding possible hardware vulnerabilities in the STM MCU that would allow extraction of encrypted key material from the key. Niibe referred to a talk presented at the WOOT 17 workshop, where Johannes Obermaier and Stefan Tatschner, from the Fraunhofer Institute, demonstrated attacks against the STMF0 family MCUs. It is still unclear if those attacks also apply to the older STMF1 design used in the FST-01, however. Furthermore, extracted private key material is still protected by user passphrase, but the Gnuk uses a weak key derivation function, so brute-forcing attacks may be possible. Fortunately, there is work in progress to make GnuPG hash the passphrase before sending it to the keycard, which should make such attacks harder if not completely pointless. When asked about the Yubico claims in a private email, Niibe did recognize that "it is true that there are more weak points in general purpose implementations than special implementations". During the last DebConf in Montreal, Niibe explained:
If you don't trust me, you should not buy from me. Source code availability is only a single factor: someone can maliciously replace the firmware to enable advanced attacks.Niibe recommends to "build the firmware yourself", also saying the design of the FST-01 uses normal hardware that "everyone can replicate". Those advantages are hard to deny for a cryptographic system: using more generic components makes it harder for hostile parties to mount targeted attacks. A counter-argument here is that it can be difficult for a regular user to audit such designs, let alone physically build the device from scratch but, in a mailing list discussion, Debian developer Ian Jackson explained that:
You don't need to be able to validate it personally. The thing spooks most hate is discovery. Backdooring supposedly-free hardware is harder (more costly) because it comes with greater risk of discovery. To put it concretely: if they backdoor all of them, someone (not necessarily you) might notice. (Backdooring only yours involves messing with the shipping arrangements and so on, and supposes that you specifically are of interest.)Since that, as far as we know, the STM microcontrollers are not backdoored, I would tend to favor those devices instead of proprietary ones, as such a backdoor would be more easily detectable than in a closed design. Even though physical attacks may be possible against those microcontrollers, in the end, if an attacker has physical access to a keycard, I consider the key compromised, even if it has the best chip on the market. In our email exchange, Niibe argued that "when a token is lost, it is better to revoke keys, even if the token is considered secure enough". So like any other device, physical compromise of tokens may mean compromise of the key and should trigger key-revocation procedures.
Algorithms and performance
To establish reliable performance results, I wrote a benchmark program
naively called crypto-bench
that could produce comparable results between the different keys. The
program takes each algorithm/keycard combination and runs 1000
decryptions of a 16-byte file (one AES-128 block) using GnuPG, after
priming it to get the password cached. I assume the overhead of GnuPG
calls to be negligible, as it should be the same across all tokens, so
comparisons are possible. AES encryption is constant across all tests as
it is always performed on the host and fast enough to be irrelevant in
the tests.
I used the following:
- Intel(R) Core(TM) i3-6100U CPU @ 2.30GHz running Debian 9
("stretch"/stable amd64), using GnuPG 2.1.18-6 (from the stable
Debian package)
- Nitrokey Pro 0.8 (latest firmware)
- FST-01, running Gnuk version 1.2.5 (latest firmware)
- YubiKey NEO OpenPGP applet 1.0.10 (not upgradable)
- YubiKey 4 4.2.6 (not upgradable)
I ran crypto-bench for each keycard, which resulted in the following:
Algorithm
Device
Mean time (s)
ECDH-Curve25519
CPU
0.036
FST-01
0.135
RSA-2048
CPU
0.016
YubiKey-4
0.162
Nitrokey-Pro
0.610
YubiKey-NEO
0.736
FST-01
1.265
RSA-4096
CPU
0.043
YubiKey-4
0.875
Nitrokey-Pro
3.150
FST-01
8.218
There we see the performance of the four keycards I tested, compared
with the same operations done without a keycard: the "CPU" device. That
provides the baseline time of GnuPG decrypting the file. The first
obvious observation is that using a keycard is slower: in the best
scenario (FST-01 + ECC) we see a four-fold slowdown, but in the worst
case (also FST-01, but RSA-4096), we see a catastrophic 200-fold
slowdown. When I
presented
the results on the Gnuk mailing list, GnuPG developer Werner Koch
confirmed those "numbers are as expected":
With a crypto chip RSA is much faster. By design the Gnuk can't be as
fast - it is just a simple MCU. However, using Curve25519 Gnuk is
really fast.
And yes, the FST-01 is really fast at doing ECC, but it's also the only
keycard that handles ECC in my tests; the Nitrokey Start and Nitrokey
HSM should support it as well, but I haven't been able to test those
devices. Also note that the YubiKey NEO doesn't support RSA-4096 at all,
so we can only compare RSA-2048 across keycards. We should note,
however, that ECC is slower than RSA on the CPU, which suggests the
Gnuk ECC implementation used by the FST-01 is exceptionally fast.
In
discussions
about improving the performance of the FST-01, Niibe estimated the user
tolerance threshold to be "2 seconds decryption time". In a new
design
using the STM32L432 microcontroller, Aurelien Jarno was able to bring
the numbers for RSA-2048 decryption from 1.27s down to 0.65s, and for
RSA-4096, from 8.22s down to 3.87s seconds. RSA-4096 is still beyond the
two-second threshold, but at least it brings the FST-01 close to the
YubiKey NEO and Nitrokey Pro performance levels.
We should also underline the superior performance of the YubiKey 4:
whatever that thing is doing, it's doing it faster than anyone else. It
does RSA-4096 faster than the FST-01 does RSA-2048, and almost as fast
as the Nitrokey Pro does RSA-2048. We should also note that the Nitrokey
Pro also fails to cross the two-second threshold for RSA-4096
decryption.
For me, the FST-01's stellar performance with ECC outshines the other
devices. Maybe it says more about the efficiency of the algorithm than
the FST-01 or Gnuk's design, but it's definitely an interesting avenue
for people who want to deploy those modern algorithms. So, in terms of
performance, it is clear that both the YubiKey 4 and the FST-01 take the
prize in their own areas (RSA and ECC, respectively).
Conclusion
In the above presentation, I have evaluated four cryptographic keycards
for use with various OpenPGP operations. What the results show is that
the only efficient way of storing a 4096-bit encryption key on a keycard
would be to use the YubiKey 4. Unfortunately, I do not feel we should
put our trust in such closed designs so I would argue you should either
stick with 2048-bit encryption subkeys or keep the keys on disk.
Considering that losing such a key would be catastrophic, this might be
a good approach anyway. You should also consider switching to ECC
encryption: even though it may not be supported everywhere, GnuPG
supports having multiple encryption subkeys on a keyring: if one
algorithm is unsupported (e.g. GnuPG 1.4 doesn't support ECC), it will
fall back to a supported algorithm (e.g. RSA). Do not forget your
previously encrypted material doesn't magically re-encrypt itself using
your new encryption subkey, however.
For authentication and signing keys, speed is not such an issue, so I
would warmly recommend either the Nitrokey Pro or Start, or the FST-01,
depending on whether you want to start experimenting with ECC
algorithms. Availability also seems to be an issue for the FST-01. While
you can generally get the device when you meet Niibe in person for a few
bucks (I bought mine for around \$30 Canadian), the Seeed online
shop says the device is out of
stock
at the time of this writing, even though Jonathan McDowell
said
that may be inaccurate in a debian-project discussion. Nevertheless,
this issue may make the Nitrokey devices more attractive. When deciding
on using the Pro or Start, Suhr offered the following advice:
In practice smart card security has been proven to work well (at least
if you use a decent smart card). Therefore the Nitrokey Pro should be
used for high security cases. If you don't trust the smart card or if
Nitrokey Start is just sufficient for you, you can choose that one.
This is why we offer both models.
So far, I have created a signing subkey and moved that and my
authentication key to the YubiKey NEO, because it's a device I
physically trust to keep itself together in my pockets and I was already
using it. It has served me well so far, especially with its extra
features like U2F and
HOTP
support, which I use frequently. Those features are also available on
the Nitrokey Pro, so that may be an alternative if I lose the YubiKey. I
will probably move my main certification key to the FST-01 and a
LUKS-encrypted USB disk, to keep that certification key offline but
backed up on two different devices. As for the encryption key, I'll wait
for keycard performance to improve, or simply switch my whole keyring to
ECC and use the FST-01 or Nitrokey Start for that purpose.
[The author would like to thank Nitrokey for providing hardware for
testing.]
This article first appeared in the Linux Weekly News.
| Algorithm | Device | Mean time (s) |
|---|---|---|
| ECDH-Curve25519 | CPU | 0.036 |
| FST-01 | 0.135 | |
| RSA-2048 | CPU | 0.016 |
| YubiKey-4 | 0.162 | |
| Nitrokey-Pro | 0.610 | |
| YubiKey-NEO | 0.736 | |
| FST-01 | 1.265 | |
| RSA-4096 | CPU | 0.043 |
| YubiKey-4 | 0.875 | |
| Nitrokey-Pro | 3.150 | |
| FST-01 | 8.218 |
In practice smart card security has been proven to work well (at least if you use a decent smart card). Therefore the Nitrokey Pro should be used for high security cases. If you don't trust the smart card or if Nitrokey Start is just sufficient for you, you can choose that one. This is why we offer both models.So far, I have created a signing subkey and moved that and my authentication key to the YubiKey NEO, because it's a device I physically trust to keep itself together in my pockets and I was already using it. It has served me well so far, especially with its extra features like U2F and HOTP support, which I use frequently. Those features are also available on the Nitrokey Pro, so that may be an alternative if I lose the YubiKey. I will probably move my main certification key to the FST-01 and a LUKS-encrypted USB disk, to keep that certification key offline but backed up on two different devices. As for the encryption key, I'll wait for keycard performance to improve, or simply switch my whole keyring to ECC and use the FST-01 or Nitrokey Start for that purpose.
[The author would like to thank Nitrokey for providing hardware for testing.] This article first appeared in the Linux Weekly News.
 and filesystem changes (!!). En vrac, a list of
changes which may be of interest:
and filesystem changes (!!). En vrac, a list of
changes which may be of interest:
 To get some idea about the expectations and current usage of alioth I created
a
To get some idea about the expectations and current usage of alioth I created
a  Introduction
I've written before about
Introduction
I've written before about  I would love to hear from others what they think of that approach, if
they have improvements or if the above copyToAllToggle function could be
merged in. Ideally, Xmonad would just parse the STICKY client messages
and do the right thing - maybe even directly in CopyWindow - but I have
found this enough Haskell for one day.
You can see the
I would love to hear from others what they think of that approach, if
they have improvements or if the above copyToAllToggle function could be
merged in. Ideally, Xmonad would just parse the STICKY client messages
and do the right thing - maybe even directly in CopyWindow - but I have
found this enough Haskell for one day.
You can see the  Beware, this would be slightly longish.
Beware, this would be slightly longish.














{kind=link}